前言
实际工程实践中,我们难免会有统一的全局服务注册中心的需求。
- 一方面,为了达到代码隔离的目的,许多服务实现散落在多个子工程、jar、aar中,更有甚者服务实现是以
runtimeOnly的形式引入——编译期不可见,只有在运行时可见; - 另一方面,统一全局服务中心本身就要求具有跨project访问服务实现的能力,这与代码隔离的目的相矛盾。
很多SPI框架都需要解决这个矛盾。前段时间无意间发现了2BAB大佬的一个库:Koncat,提出了一种跨工程代码聚合的新思路。我对这个库进行小小小的拓展,使用了Kotlin Symbol Processing(KSP) + 自定义Gradle Task实现了无侵入零反射的SPI方案,便有了本篇文章。
Service Provider Interface
在我的理解中,Service Provider Interface(SPI)是一种获取接口实现的机制,使用者只需要提供接口类,即可获取对应接口的实现类实例。
Java本身就提供了SPI机制,其实现为ServiceLoader。其原理是通过读取resources/META-INF/services/文件夹下的文本文件(文件名为接口全限定名,内容为接口实现类全限定名),然后反射创建实例,在调用方请求获取实现类的时候,再把这些实例返回给你。
SPI框架更多关心的是根据接口获取接口实现类的逻辑,有将接口到实现类的映射埋藏在resources文件夹下,如这里提到的ServiceProvider,也有使用注解的方式处理接口到实现类的映射。由于注解的方式更加方便,因而很多SPI框架都采用着了这种方式。
SPI实现方案的历史
在我的认知中,业界SPI框架的实现,是在不断压榨编译期性能和运行时性能下,一步一步发展过来的。
注解 & 反射
在我刚刚接触Android开发那会儿,SPI的实现方案是注解处理器 + 运行时反射。
例如,有一个服务和一个实现:
1 |
|
在编译期会扫描所有的@Service和@ServiceImpl注解,生成以下类:
1 | class ICamerService_Impl_Holder : ServiceHolder<CamerService> { |
在运行时,反射查找类:
1 | class ServicePool { |
这种方案没有什么问题,既能够在编译期做到代码隔离,在运行时也能获取到真正的实现,很好的解决了上面的矛盾点。
但是有一个微小的瑕疵:在运行时使用到了反射。在首次反射的时候,因为虚拟机没有对代码进行JIT优化,所以会慢一点;如果是在启动的时候,性能的损耗则会放大。但瑕不掩瑜,注解 + 反射的方案是能够很好的工作的。
Transform & 字节码操纵
注解 + 反射有微小的性能问题,是因为为了在源码期进行代码隔离,访问不到真正的实现,不得已才使用了反射。这个方案的问题是取舍问题,而不是能不能实现的问题。
既然源码期因为代码隔离而不能实现聚合,那我们不妨把时机推后一点,不要在源码期进行代码聚合。
后来了解到,Android Gradle Plugin(AGP)提供了Transform机制:它提供了从*.class文件转化成*.dex文件前的hook点,开发者能对参与编译的*.class文件进行修改,或者新增、剔除*.class文件,结果会参与到编译成*.dex文件过程中。
当源码被编译成了*.class文件后,就已经没有了工程的概念,这个时候我们就可以进行代码聚合,而不用担心代码隔离的问题。因此,我们可以实现一个Transform,在编译期扫描得到所有的接口实现类,并通过字节码操纵技术生成或修改*.class文件并输出:
1 | class ServiceProviderInterfacePlugin : Plugin<Project> { |
在运行时,我们无需反射,也能像直接访问类一样去获取实例:
1 | class ServiceRegistry { |
Transform机制也能够很好的解决代码隔离与代码聚合之间的矛盾。与注解 + 反射方案不同的是,Transform方案的扫描逻辑全部交给了实现的Transform类;生成的代码,也变成了从生成源码到生成字节码。
但是Transform方案也有小小的瑕疵:
- 需要手动处理增量编译,否则会拖慢编译速度;
- 由于Transform机制的内部实现,Transform运行过程中会有一些冗余的IO,间接拖慢了编译速度,还是有些许的优化空间的;
并且,从AGP的Release Note和未来的时间线可以看到,Transform机制已在AGP 7.0上废弃,并将在AGP 8.0上移除。基于Transform被废弃并马上被移除的现状,可以考虑使用AGP新的字节码操纵方案来代替。
AsmClassVisitorFactory
既然Transform机制已经被废弃,并且在不久的将来会被移除,AGP官方就必定会提供一个替代方案。正巧,如果需要实现修改字节码功能,可以使用AsmClassVisitorFactory 来代替。
1 | interface AsmClassVisitorFactory<ParametersT : InstrumentationParameters> : Serializable { |
从接口定义可以看出,我们可以通过isInstrumentable 接口返回我们是否要处理这个类;如果我们要处理这个类,则需在createClassVisitor 方法返回一个ClassVisitor,通过这个ClassVisitor 来修改这个类。
但就目前提供的接口来说,AsmClassVisitorFactory 可能还不太适合用于处理SPI的逻辑,原因有二:
- SPI的逻辑需要扫描全部类后,再修改or新增类,然而
AsmClassVisitorFactory目前没有提供这一时机的回调; AsmClassVisitorFactory内部已经维护好了增量逻辑,当新增or移除服务or服务实现时,我们无从得知;
这个时候就进退维谷,十分尴尬了:一方面旧有的Transform机制已经废弃,即将移除;另一方面新的替代方案尚不成熟,无法满足需要。因此我们需要考虑其他的方案。
KSP & 自定义Gradle Task
注解+反射方案能解决代码隔离与代码聚合的问题,但是运行时的性能有小小的瑕疵;
Transform方案也能解决代码隔离和代码聚合的问题,且运行时没有性能损耗,但增量编译逻辑较难维护,且Transform机制马上被移除;
字节码操纵的替代方案AsmClassVisitorFactory 无法适用于实现SPI的逻辑,因为它深度封装了执行逻辑,一些必要的细节开发者无法触碰到。
我认为我们可以自己实(zao)现(ge)一(lun)个(zi)支持增量扫描 & 字节码操纵的SPI插件。我简单拆解一下,至少要解决以下问题:
- 单一工程增量扫描;
- 跨工程聚合服务和接口的信息;
- 生成服务与实现之间的映射字节码;
- 产物字节码汇入到编译流程中;
增量扫描与代码聚合
目前已有开箱即用的、支持增量逻辑的代码扫描方案有:
kapt是一个支持kotlin语言的注解处理器,支持增量扫描,支持产物为java代码的多轮处理;
KSP是google开发的源码级别的代码处理器,比kapt性能更好,功能更强,支持增量扫描和多轮处理;
Transform马上被移除,不做讨论。
由于KSP的性能相较于kapt更好,并且KSP支持产物为kotlin代码的多轮处理,因此最终选用KSP作为代码扫描工具。
使用KSP实现单一工程增量扫描
在SymbolProcessor 中,获取服务和实现的信息
1 | class MetadataCollectProcessor( |
使用KSP跨工程信息聚合
跨工程信息聚合,关键在于能够在某一工程(主工程)访问到其他工程的信息,并对这一信息聚合,为当前工程所用。KSP的Resolver提供了一个跨工程访问代码的接口,可以通过给定包名,获取当前工程和其他工程下该包名的所有信息:
1 | interface Resolver { |
我们可以利用这一点,约定每个依赖的工程、jar和aar都把各自的服务、实现信息写到指定包名中,再通过这个接口一次性获取当前工程以及其依赖的工程、jar、aar的所有服务、实现信息,实现信息聚合,并将聚合结果写入到resources下;
1 | class MetadataAggregateProcessor( |
小结
KSP帮助我们实现单工程扫描和多工程信息聚合,总体工作流程如下图:
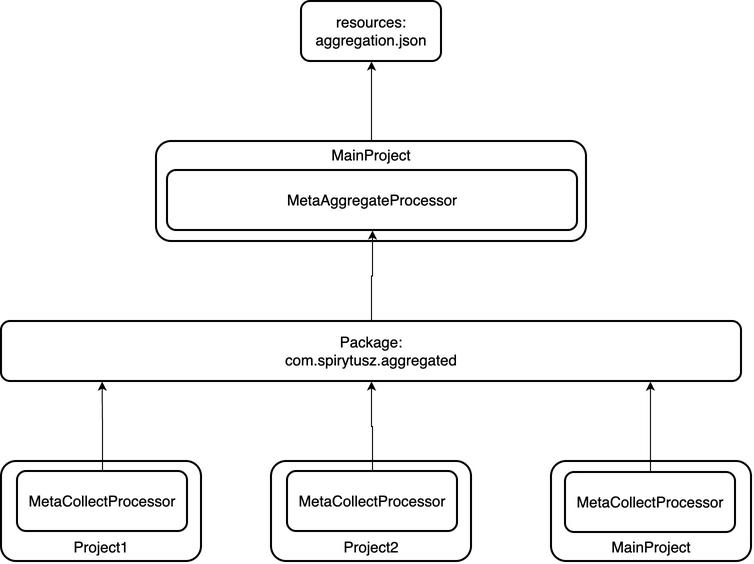
自定义Gradle Task实现插入代码
有了所有服务和实现的信息,就可以考虑代码生成的逻辑了。我们可以自定义Gradle Task来完成插入服务、实现信息的逻辑。插入的代码可以是源码,也可以是字节码。但由于我们需要代码隔离,因此我们只能选择插入字节码。
插入字节码又有两种方式:
- 编辑现有的
*.class文件; - 创建一个新的
*.class文件;
编辑现有的*.class文件,我们需要知道目标*.class文件存放在哪里,直接遍历工程目录不可取,可以考虑在compileKotlin(Java语言对应compileJavaWithJavac)执行完毕后,获取其输出文件然后挨个遍历搜索;找到后通过字节码操纵技术执行代码插入逻辑。
创建新的*.class文件,我认为可以将存放service到impl映射的代码单独剥离出来,使用compileOnly的形式引入。通过使用compileOnly的形式引入,使之不参与编译流程,我们也就能在编译流程中自行生成字节码,再将产物汇入到编译流程,存在于最终产物中。
为了简便实现,我选择了第二个方案:源码期提供占桩jar,编译期生成字节码文件,达到偷梁换柱的效果。
占桩Jar
占桩Jar中提供一个容器存放service到impl的映射关系:
1 | ("ServiceRegistry") |
在runtime模块以compileOnly的形式引入:
1 | // build.gradle (spi-runtime) |
做到源码期能够直接访问:
1 | package com.spirytusz.spi.runtime |
编译期生成代码
占桩代码实际上不参与编译,其作用仅仅只是为了通过编译,需要在编译期生成对应的代码。
瞪眼法观察占桩代码,其对应的Java代码如下:
1 | public class ServiceRegistry { |
- ①处就是存放服务-实现映射的字段;
- ②处是编译器帮助我们生成的无参构造方法;
- ③处是编译器帮助我们为public val的字段生成的getter方法;
- ④处是为了初始化①处变量的静态代码块,后面可以用来插入服务-实现映射的代码;
只要生成这四处代码就可以了。关键在于服务-实现映射代码的生成,举个例子,使用javap反编译出字节码:
1 | javap -c -v -s -l ServiceRegistry.class |
Java代码与字节码的映射关系如下:
1 | public class ServiceRegistry { |
使用ASM框架对着字节码翻译即可完成生成字节码的逻辑。
完成了字节码的生成逻辑,就可以考虑Task的输入输出了,定义一个task:
1 |
|
输入即inputMetadata,是一个包含了服务实现映射关系的json文件;
输出即outputClasspath ,是生成字节码文件的所在目录;
然后在配置阶段配置输入输出,以及依赖关系:
1 | val outputClasspath = layout.buildDirectory.dir("intermediates/moses/$variantName") |
汇入编译流程
生成的outputClasspath 是孤立的,合成dex文件的DexArchiveBuilderTask是不知道它的存在的。因此我们需要告诉DexArchiveBuilderTask我们生成代码,使得我们生成的代码能够参与合成dex的流程。
1 | val outputClasspath = layout.buildDirectory.dir("intermediates/moses/$variantName") |
这样DexArchiveBuilderTask 就会将我们生成的字节码文件一并合成为dex文件。
自此,我实现的SPI框架总算完成了。
与Gradle缓存
所以,这与Gradle缓存有何联系?这里的缓存分为两种:
- KSP自身利用Gradle缓存机制实现的缓存;
- 自定义Task的缓存;
KSP的缓存
KSP的增量扫描逻辑由缓存来保证。Google也在Incremental processing描述了这块逻辑。
KSP会根据产物的类型:Aggregating和Isolating来决定是否重新处理。我实现的SPI框架就分别使用到了这两种产物类型:
Aggregating
An aggregating output can potentially be affected by any input changes, except removing files that don’t affect other files. This means that any input change results in a rebuild of all aggregating outputs, which in turn means reprocessing of all corresponding registered, new, and modified source files.
MetadataCollectProcessor的产物就是aggregated的。通过指定产物为aggregated的,使得在指定的服务和实现代码发生变化时,KSP能够将变化告诉MetadataCollectProcessor,我们才能重新处理,扫描出正确的服务和实现。例如,当代码修改没有触及到服务和实现类时,KSP并不会让
MetadataCollectProcessor重新处理。一旦修改触及到了服务或实现,KSP就会将所有的服务和实现交给MetadataCollectProcessor,MetadataCollectProcessor便会重新处理并生成相应的代码。Isolating
An isolating output depends only on its specified sources. Changes to other sources do not affect an isolating output. Note that unlike Gradle annotation processing, you can define multiple source files for a given output.
MetadataAggregateProcessor就是isolating的,这样KSP就知道MetadataAggregateProcessor指关注指定包名的代码,只有这个包名下的代码发生了变化,KSP才会通知MetadataAggregateProcessor重新处理。例如,当
MetadataCollectProcessor的产物没有变化时,KSP就不会重新执行MetadataAggregateProcessor;否则,一旦某个工程的MetadataCollectProcessor的产物发生改变,就会触发MetadataAggregateProcessor的重新处理。
自定义Task缓存
自定义Task缓存是基于Gradle缓存的,实现方式是:
- 通过
@CacheableTask将Task指定为CacheableTask; - 通过
@Input和@PathSensitive告诉Gradle输出的文件是什么;
通过上面两个步骤,Gradle就能够帮我们维护缓存。经过KSP处理器处理后,会生成一个聚合了服务&实现信息的json文件。
如果这个json没有变化时,Gradle就不会执行这个自定义Task,并且能在输出中观察到这个task的状态是UP-TO-DATE的;
如果这个json发生了变化,Gradle则会重新触发执行这个task。
总结
在扫描逻辑上,我借助了KSP的增量扫描机制来进行服务&实现的收集,并在主工程中聚合起来,生成一个带有所有服务&实现的json文件;
在代码生成逻辑上,我自定义了一个Gradle Task,以执行字节码生成的逻辑;
在缓存管理上,我借助了Gradle缓存机制,将自定义Gradle Task标记为Cacheable的,当json文件没有改变时,Gradle会跳过执行该Task的Action;
最后,将输出的字节码文件输入到DexArchiveBuilderTask 中,使得生成的字节码能够参与Dex文件的合成,产物dex文件中才会带上我生成的字节码。